
保守ASIC不成编程,于是DSA应运而生。常乔雨暗示:“DSA芯片正在机能和矫捷性之间找到均衡点,成为ASIC和GPGPU(通用图形处置器计较)之外的另一条手艺径。DSA连系了ASIC的高机能劣势和GPGPU(通用图形处置器)的编程矫捷性,专为特定范畴的计较需求设想,特别合用于泛安防和从动驾驶等明白场景。”?。
做为A股AI算力芯片龙头可谓风头无两,Wind数据显示,客岁寒武纪股价上涨387。55%,同期科创100指数则下跌8。56%。
也就是说,当下AI仍以锻炼为从导,GPU仍是支流。而将来,跟着AI手艺的普遍落地,推理市场规模或大幅跨越锻炼环节。而推理环节,恰是AI ASIC的从疆场。
壁仞科技向记者供给的材料也显示,公司正结合客户、合做伙伴、科研机构配合鞭策异构GPU协同锻炼生态,具体包罗:中国挪动、中国电信、中兴通信、商汤科技、国网智能电网研究院无限公司、上海智能算力科技无限公司、上海人工智能尝试室、中国消息通信研究院等。
不外,寒武纪、燧原科技的芯片可能更方向于DSA(范畴公用架构),不属于保守不成编程的ASIC,而是广义的ASIC。
进入2025年,1月15日,沐曦股份也启动了上市。若四家全数上市成功,将大幅扩展A股AI算力厂商投资标的的供给。
而摩尔线程创始团队来自全球GPU巨头英伟达,其创始人兼CEO张建中曾任英伟达全球副总裁、中国区总司理。
材料显示,智芯是国内率先支撑智算芯片夹杂锻炼的通用GPU厂商。其“天垓”和“智铠”产物系列,普遍使用于支流大模子的锻炼、微调以及推理使命。2024年,智芯加入了正在上海市通信办理局和上海市数据局的支撑下,多家单元结合开展的跨域异构算力收集尝试验证工做,异构混训效率可达97。5%。
黑芝麻智能也对记者暗示:“黑芝麻智能的芯片架构兼具ASIC的高机能和GPGPU的矫捷性,芯片产物能够归为ASIC芯片类别,和以上芯片(寒武纪、华为海思昇腾、燧原科技)架构雷同,都具备矫捷编程的扩展性。”。
智芯副总裁邹翾对《每日经济旧事》记者暗示:“异构计较正在锻炼和推理范畴都占领着主要地位。正在锻炼范畴,面临大规模数据集和复杂模子布局,单一类型芯片往往难以满脚计较需求。异构计较通过整合多种分歧架构芯片,能够加快锻炼过程,削减锻炼时间和成本。正在推理范畴,及时性要求极高,异构计较可以或许按照分歧的推理使命特征,矫捷调配硬件资本。例如正在处置图像、语音等特定类型数据时,通过分歧芯片的协同工做,快速完成推理,输出精确成果。”。
按照国联证券研报,AI大模子的快速成长鞭策“算力”“存力”需求快速增加。取此同时,对“运力”也提出了更高的需求。系统需要更高的带宽,更快的传输。但内存的机能提拔速度远低于处置器的机能提拔速度,导致处置器无法充实阐扬其计较能力。
这几家接管IPO的企业中,燧原科技创始团队有AMD布景,其创始人兼COO张亚林于2008年插手AMD,历任资深芯片司理、手艺总监。已经做为全球芯片研发次要担任人之一,正在AMD上海研发核心成功带领开辟并量产了多颗世界级芯片,具有丰硕的工程和产物化实和经验。
他弥补暗示:“全体来看,ASIC、GPGPU强调通用性,而DSA则测验考试去连系两者的长处,带来性价比和效率更高的算力。”!
壁仞科技暗示,这一异构GPU协同锻炼方案最终实现了国产GPU和英伟达GPU的异构共存,冲破异构算力孤岛难题,加速国产GPU的落地迁徙,帮力国产大模子落地。此外,该方案赋能整个算力财产成长,壁仞HGCT方案具备普适性、易用性、兼容性,帮力最终客户实现多种异构算力聚合,最大化异构GPU集群操纵效率。
国内CXL高速互联厂商国数集联告诉《每日经济旧事》记者:“NVLink具备高带宽和低延迟的长处,但存正在生态封锁、价钱高贵等问题。次要使用正在英伟达产物中。CXL基于PCIe的根本上成长而来,专注于优化处置器取加快器之间的通信。CXL可以或许供给高带宽、低延迟的通信,并支撑先辈的大容量低延迟内存协同特征。CXL也是独一横跨运力和存力的互联尺度、独一横跨通用办事器和AI办事器的互联尺度。”?。
天智数芯暗示:“目前这种外挂AI芯片的AI PC已有原型,而且曾经有用户正在利用。跟着AI正在PC端使用场景不竭拓展,如智能创做、数据阐发等,对算力需求剧增。将AI算力芯片做成‘外挂’,便于用户按照本身需求矫捷升级,提拔AI机能,就像现正在人们按需选择显卡。同时,这也有帮于降低PC全体成本,推进AI手艺正在PC范畴的普及。”。
正在边缘侧,AI PC又将若何成长呢?将来AI算力芯片能否可能做为零丁的“外挂”芯片,雷同于显卡搭配正在AI PC之中?
目前,国际上支流AI ASIC厂商为博通、Marvell。需要留意的是,博通不只具有AI ASIC设想能力,其配套收集营业也十分强大,好比以太网互换芯片、PCIe/CXL Retimer等。而英伟达算力范畴的三大壁垒,包罗GPGPU芯片、NVLink和CUDA生态。
目前国内也有较多的AI ASIC厂商。那么,国数集联正在高速互联范畴有哪些奇特的劣势,能否成心取AI算力芯片厂商合做,配合研发、拓展市场?
沐曦股份创始团队同样来自AMD,其创始人陈维良曾任AMD全球GPGPU设想总担任人;两位CTO(首席手艺官)均为前AMD首席科学家,目前别离担任公司软硬件架构。
正在寒武纪“独领”的二级市场之外,国内还有一批优良的AI算力芯片企业尚未登岸本钱市场,如壁仞科技、智芯、燧原股份、摩尔线程、沐曦等。此中,壁仞科技、燧原股份、摩尔线程、沐曦目前已进入上市阶段。
别的,目前接管IPO的四家厂商中,三家眷于GPU线,一家眷于ASIC线。当下,以英伟达为代表的GPU算力厂商仍是市场支流,而近期以博通为代表的ASIC线也逐步遭到普遍关心。

大模子成长敏捷,也对各大厂商软硬件连系能力提出更高要求。而国内不少GPGPU厂商,也起头“异构计较”。
正在国泰君安证券研报中,谷歌TPU、华为海思昇腾910均被分类为ASIC。此外,燧原股份的云燧T20取寒武纪的NPU正在全体机能上也取谷歌比肩。
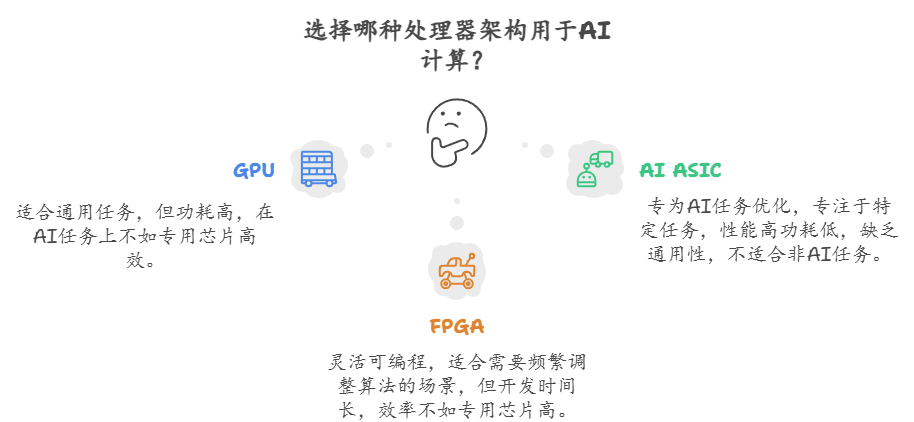
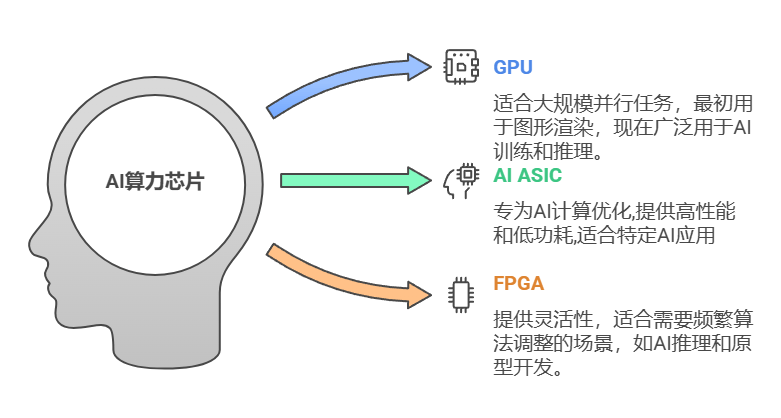
AI算力芯片次要能够分为GPU(图形处置器)、AI ASIC(人工智能公用处置器)和FPGA(现场可编程门阵列)三种。目前,国内GPU厂商代表有壁仞科技、天智数芯、摩尔线程和沐曦等;AI ASIC厂商代表有华为海思昇腾、燧原股份、地平线、黑芝麻智能、比特等。
能够看出,除了寒武纪外,国内未上市的企业中,也有较多GPGPU厂商、AI ASIC厂商,且正在“运力”、软件生态范畴,国内厂商也正在积极结构。
常乔雨认为:“当前,AI ASIC的使用次要集中正在推理使命上,虽然部门产物也涉及锻炼范畴,但推理明显是其焦点疆场。这是由于推理使命具有固定的计较模式和高吞吐量需求,很是契合ASIC硬件固化的高效特征。取此同时,推理的市场空间将来也将显著跨越锻炼。跟着人工智能手艺正在各行业的加快渗入,终端设备和云端推理的需求量快速增加,涵盖了从智能家居到工业从动化再到车载计较的多样化场景。而推理使命的高频挪用和长生命周期特点,也决定了这一市场的规模潜力将远超一次性投入较高的锻炼环节。”。
按照国泰君安证券研报,AI芯片次要分为三品种型:通用型(GPU)、半定制型(FPGA)、定制型(ASIC)。三类芯片代表别离有英伟达(NVIDIA)的GPU、赛灵思的FPGA和Google的TPU(一种特地为机械进修使命设想的AI ASIC)。GPU的计较能力最强,可是成本高、功耗高;FPGA可编程,最矫捷,可是计较能力不强;ASIC体积小、功耗低,适合量产,可是研发时间长,且不成编纂,前期投入成本高。
虽然位列Wind GPU指数(8841701。WI)成分股,但按照寒武纪招股书,其将本人的产物取保守芯片CPU、GPU等进行了区分,称“次要研发通用型智能芯片”,而不是公用型智能芯片(ASIC)。不外,正在多家券商和征询机构的研报中,均将其产物列为了ASIC。

黑芝麻智能方面告诉《每日经济旧事》记者:“黑芝麻智能的智驾芯片正在高机能、低功耗、矫捷性、跨域融合、市场定位和端到端算法参考模子等方面都有显著劣势。因为黑芝麻智能智驾芯全面向特定场景,因而算力的操纵率、能效比城市更高。正在矫捷性方面,黑芝麻智能的芯片设想融入了可编程性,使其正在必然程度上具备GPGPU的矫捷性。”。

头豹研究院AI行业高级阐发师常乔雨也告诉《每日经济旧事》记者:“目前国内处置AI ASIC研发的厂商次要包罗寒武纪、地平线、燧原科技、黑芝麻智能和比特等。”。
对于GPU线取ASIC线的好坏,TrendForce集邦征询阐发师邱珮雯答复《每日经济旧事》记者认为:“ASIC正在可见的将来不会完全代替GPU,ASIC凡是是特地为某种特定使用或运算去设想的芯片,如锻炼或推理,方向特定客户定制化;而GPU设想为通用运算,对于施行多样使命较具矫捷性,凡是为尺度品,合用于大都客户,且相较于高阶英伟达芯片如B200,ASIC目前开辟运算效能落差仍大。因而,ASIC和GPU有各自的方针市场及使用。”!
2024年8月以来,国内四大AI算力厂商连续启动IPO。2024年8月26日,AI ASIC范畴代表厂商燧原科技启动IPO;GPGPU范畴代表厂商壁仞科技于9月11日启动IPO;11月12日,GPU厂商摩尔线程启动IPO。
国数集联暗示:“公司面向人工智能数据核心(AIDC)、云办事商、办事器厂商以及运营商,供给先辈的高速互联算法、芯片及方案。目前,公司的焦点产物包罗CXL Switch芯片、模块以及硬件全体方案。AI厂商、运营商展开合做,旨正在供给高效的数据传输和联合方案。”。
上一篇:寒武纪初次实现季度盈利国产AI芯片兴起中